The Storm framework is an open-source distributed and fault-tolerant real-time processing system used by many companies including Groupon, Twitter, Alibaba, Klout, etc. It’s the Hadoop of real-time processing and it can be used for real-time analytics, online machine learning and parsing social media stream, just to name a few. This post will help you getting started with Storm via a sample Java project that you can run on any desktop environment.
Few months ago I had the pleasure to attend the Data + Visualization Toronto Meetup‘s hands-on session on Storm where we built a sample Storm topology that parsed Twitter’s sample feed and printed a list of top tweets based on their retweet counts in every 5 minutes.
It’s pretty amazing that starting from scratch you can get a basic storm topology up and running on a local box in a few minutes time. Check out this slightly modified version of the above mentioned sample project: https://github.com/davidkiss/storm-twitter-word-count. It parses the same Twitter sample feed using twitter4j, collects all the words in the tweets and at every 10 seconds it prints out the words with the most count.
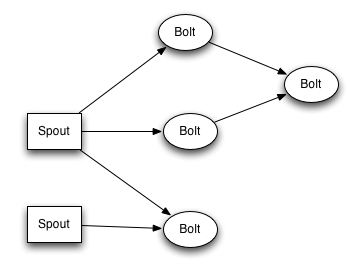
While in Hadoop you have Map-Reduce jobs, in Storm you have two types of nodes: Spouts and Bolts. These nodes can receive data (tuples), process them and emit them to other nodes so they can be chained together.
Spout
Spouts are nodes that produce data to be processed by other nodes. It can read data from HTTP streams, databases, files, message queues, etc. Here’s the code for the Spout that parses a Twitter feed using Twitter4J: https://github.com/davidkiss/storm-twitter-word-count/blob/master/src/main/java/com/kaviddiss/storm/TwitterSampleSpout.java
Bolt
Bolts can both receive and produce data in the Storm cluster. Here’s the code for a Bolt that receives tweets and emits all its words: https://github.com/davidkiss/storm-twitter-word-count/blob/master/src/main/java/com/kaviddiss/storm/WordSplitterBolt.java
Topology
A topology is an object that configures how the Storm cluster will look like: what Sprouts and Bolts it has and how they are chained together.
Here’s the code for the topology used in the sample: https://github.com/davidkiss/storm-twitter-word-count/blob/master/src/main/java/com/kaviddiss/storm/Topology.java.
Leave a comment below if you’re considering giving Storm a try or already using it.
—-
Update
Since I got many comments on running this from storm command line, I just updated the code to create a fat jar that can be run using this command:
storm jar storm-twitter-word-count-jar-with-dependencies.jar com.kaviddiss.storm.Topology